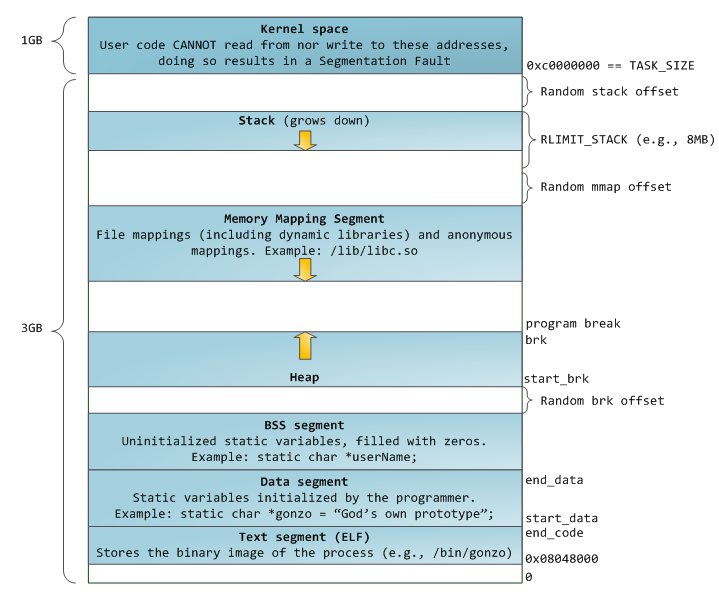
CPU架构
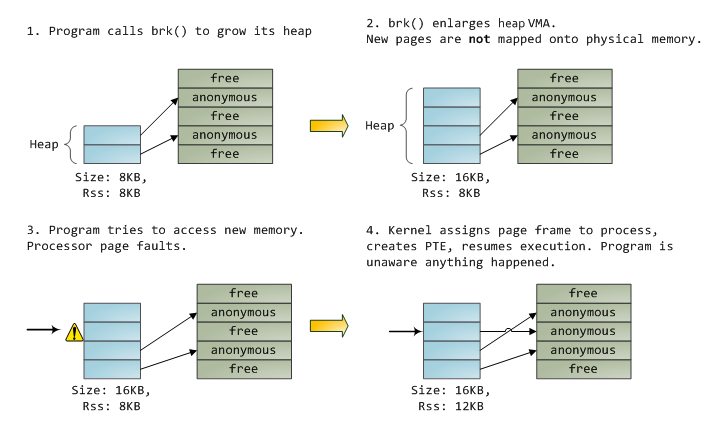
早期时,个人电脑及小型服务器的架构如下:所有CPU之间是通过FSB(Front Side Bus, FSB)进行相互连接,并通过它来连接北桥,北桥连接高速设备(如主存等),通过北桥可以连接南桥,南迁连接低速设备(如硬盘、外设等)。

这样的架构有这样一些特点:
- CPU之间的交互需要共用连接比较的总线(FSB)
- 每个RAM只有一个接口
- CPU同主存之间的交互要通过北桥
- CPU同南桥上的设备间的交互必须通过北桥
这样的一个架构容易引入这样一些瓶颈:
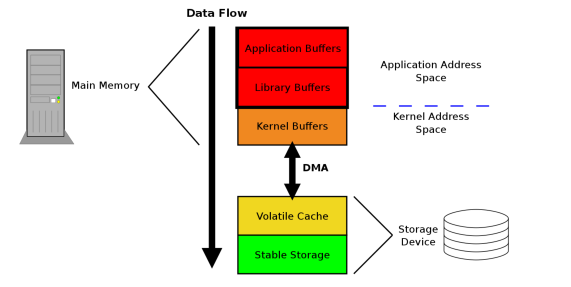
- 第一个瓶颈是对RAM的访问。早期时,所有设备的交互都要通过CPU来进行,这样会严重影响整个系统的性能。为了解决这个问题,直接内存访问(DMA,direct memory access )技术被发明出来了,DMA允许外设通过北桥直接同RAM进行交互。这样能极大降低CPU负载,提升系统整体性能。
- 第二个瓶颈是通过从北桥连接RAM的总线。早期时系统是通过一条总线来连接所有RAM,所以无法并行访问内存,最近的RAM都支持多条总线连接来提升内存访问带宽
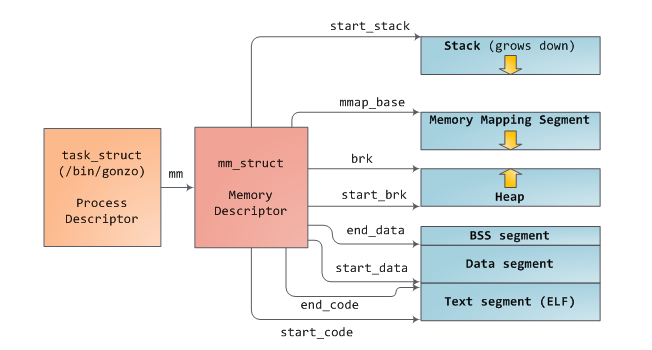
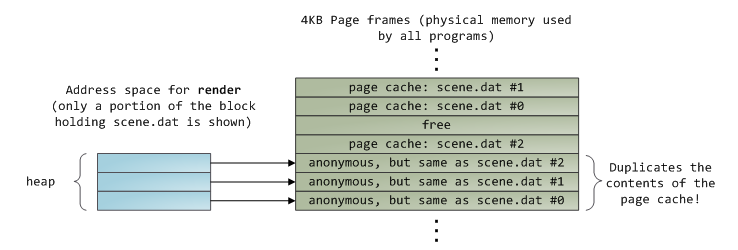
但内存访问带宽受限时,合理安排内存访问顺序对于提升系统性能是非常重要的。众所周知,即使使用了CPU缓存后,CPU的运行速度(内部寄存器的访问速度)也比主存的访问速度快多了。如果多个线程、CPU核心、CPU处理器同时访问某块内存,那么整体的内存访问延迟是很高的。在一些现代系统中,在北桥上不是直接连接RAM,而是会连接一些外部内存分配器,如下所示:

这个架构的好处是有多个内存总线存在,能提升整体的内存访问带宽,同时能提升系统的内存总量,并且通过访问不同内存条的方式可以降低并发内存访问的延迟。此时,系统的整体内存访问带宽主要受限于北桥的传输速度,这即使传统SMP(对称多核处理器)架构。
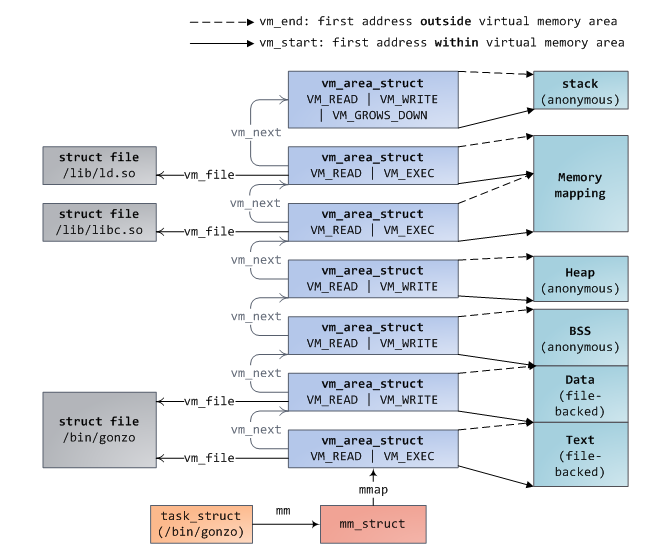
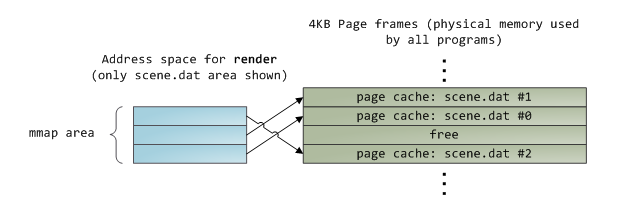
在北桥之间接入多个外部内存分配器并不是提升内存访问带宽的唯一方法,在一些系统中,内存分配器被放入CPU中,内存条也是直连每个CPU的,如下所示:
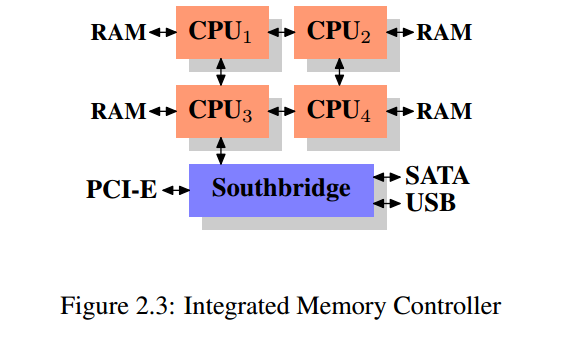
这就是NUMA(非均匀性内存访问)架构,采用这种架构也有这样的问题:
- 内存访问不再是对称的,本地内存还能以正常的速度访问,然而访问其他处理的内存需要通过对应的CPU来进行交互,这样会导致访问远程内存的速度较慢
存储器
随机访问存储器(RAM)
RAM分为两类:静态随机访问存储器(SRAM)和动态随机访问存储器(DRAM)。SRAM比DRAM访问速度快得多,但也更加昂贵,SRAM通常都是用来做高速缓存,DRAM通常用来做主存。SRAM与DRAM都是易失性存储,只要断电,其中存储的数据便会丢失。
磁盘
磁盘是应用最广的数据存储设备,容量比RAM大得多,但是访问延迟也高。从磁盘读取信息时间为ms级别,DRAM的访问速度比磁盘快10万倍,而SRAM比磁盘快100万倍。
磁盘是由盘片构成的,每个盘片有两面被称之为表面,盘片中央有一个可旋转的主轴,盘片以固定速率围绕主轴旋转,如下图所示展示了一个典型的磁盘结构:
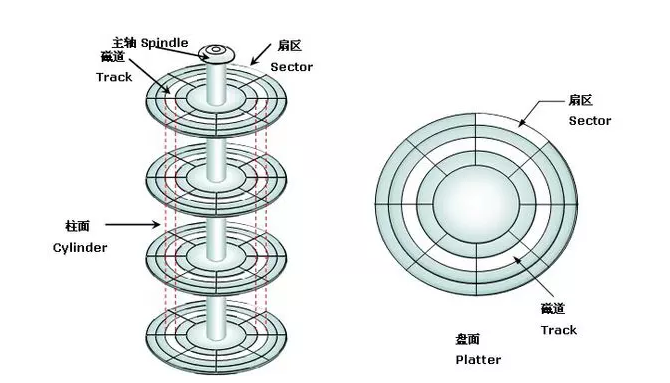
每个表面由一组称为磁道的同心圆组成,每个磁道被划分为一组扇区,扇区间由间隙隔开,扇区是磁盘存储的最小单位,柱面是所有表面上到主轴距离相等的磁道的集合。
磁盘以扇区为基本单位,使用磁头来读写盘面上的数据,对扇区的访问时间主要由一下三个部分组成:
- 寻道时间:磁头移动到目标扇区所在磁道的位置
- 旋转时间:盘面旋转将目标扇区转到到磁头下
- 传送时间:磁头读取扇区中的数据
相对来说,传送时间远小于寻道时间和旋转时间,这也是为什么硬盘的顺序读写要比随机读写速度快得多。因为寻道时间和旋转时间大致是相等的,所以将寻道时间乘于2是估计磁盘访问时间的简单办法。
固态硬盘(ssd)
固态硬盘是一种基于闪存的技术,相对磁盘来说,ssd上随机访问的速度较顺序访问的速度不会相差太多。
各级存储设备访问延迟
以一个CPU时钟周期为单位,各级设备的访问延迟如下:
| 设备 | 延迟(时钟周期) |
|---|---|
| L1 | 2~3 |
| L2 | 15 |
| L3 | 30~40 |
| Memory | 100~200 |
| Disk | 1亿~2亿(30ms)左右 |