Minix
Linux内核在最早发现的时候并没有实现自己的文件系统,而是直接引入了Minix中的文件系统,它的主要结构如下:
- 一个
boot sector位于磁盘的第一个扇区内,里面存储的是Minix系统的启动信息和分区表 - 每个分区的第一个block中存储的是
superblock,里面记录了磁盘上其他分区的结构和对应物理磁盘上的位置 inode bitmap:里面记录了inode的使用情况- inode信息:一个inode对应一个文件,inode中记录了文件的元数据
zone bitmap:记录磁盘块的使用情况data zone:实际存储文件数据的地方
其中,inode存储的是文件的元数据,包括文件大小、文件所属、修改时间等,但是inode中并没有存储文件名。inode中同时存储了文件所占用的block位置,在Minix和EXT1~3文件系统里,inode中是包含9个直接指针、7个1级指针、2个2级指针用以指向对应的data block
EXT
最初的EXT文件系统是为了克服Minix文件系统的大小限制而开发的,它是基于Unix文件系统而来,但是目前能获取的关于EXT文件系统的信息较少,因为它也存在较多问题并 很快被EXT2文件系统所替代
EXT2
EXT2的元数据结构跟EXT是一样的,但是它更具前瞻性,因为它预留了较多空间供元数据使用。和Minix一样,EXT的第一个扇区也是boot sector。一个EXT2上的空间会被切分成多个块组进行管理(一个块组通常是8MB,块组也叫柱面组,基于柱面做分组能有效降低旋转时间),如下所示为一个块组的基本结构,其中数据分配的基本单元为块,一个块的大小通常为4K:
一个块组的第一个块为superblock,其中存储的都是整个文件系统的元数据,如果元数据损坏,可以通过dd将备份超级快复制过来进行修复。通常这部分元数据都会备份存储在多个块组上用以提高系统可用性。ext4的驱动在工作时都是查询和修改第一个块组内存储的元数据,dumpe2fs可以查看superblock中的元数据:
1 | # dumpe2fs /dev/sda1 |
此外每个块组可能会有一小段的预留空间用来存组描述符(GDT),每个块组有自己的inode和block位图用以管理自身的inode和block,所以一个EXT2的磁盘结构如下所示:
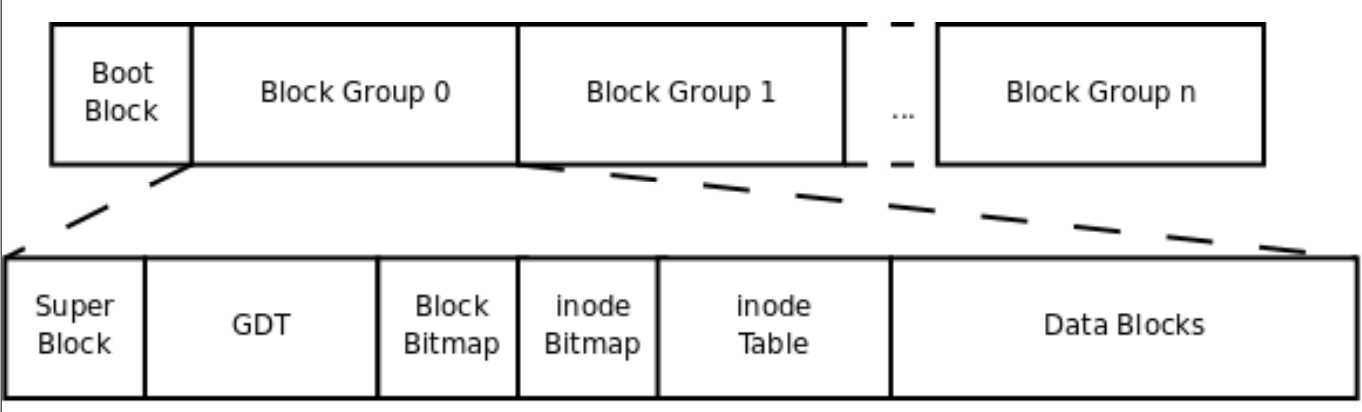
EXT2的最大问题就是在发生奔溃后需要花费较长时间才能恢复,因为fsck需要花费很长时间修复文件系统中的不一致问题。
EXT3
ETX3最终要的修改就是引入了日志来解决ETX2恢复时间较长的问题,日志里记录了文件系统上最近的修改。此时,数据不是直接写入磁盘数据区,而是先写入日志中,当数据正在持久化后,就可以回收日志。当文件系统奔溃后,通过回放日志就可以恢复文件系统,避免数据丢失。显而易见的是,引入日志虽然提高了数据的可靠性,但是会带来性能的下降,所以EXT3也提供了选项供用户在数据可靠性和性能之间做平衡。
EXT4
EXT4主要是提升了文件系统整体的性能、可靠性及容量。为了提高可靠性,加入了元数据和日志的校验。此外,ext4在提升文件的连续性上也做了非常多的工作,如extent的引入、更加合理的block、inode分配策略等。数据分配的基本单元由block变为extent了,一个extent是磁盘上的一段连续空间,extent的引入使得一个inode能使用更少的数据指针描述一个物理上连续的大文件,在有效提升单个文件的最大尺寸的同时有效减少文件元数据的大小。
此外,EXT4也引入了一些其他分配策略来提升文件的连续性,降低文件内部的碎片,主要如下:
- 将新创建的文件分散到磁盘上来减少磁盘碎片,而不是将文件都集中在磁盘开头部分
- 文件分配算法会尽量将文件随机分布到块组上,同时尽量保持同一文件的extent处以同一块组,extents间尽可能靠近,从而缩短寻道和旋转时间
- 采用预分配策略来创建新文件,同时新文件不会紧跟现有文件,防止现有文件的碎片较多
需要注意的是,文件内部碎片的这么优化可能会导致整体磁盘空间碎片的增加,这也需要做一个权衡。
下面来详细看看EXT4的主要结构。
Super Block
SuperBlock中记录了整个文件系统的元数据,如block数目、inode数目、block group的情况等,superblock如果彻底损坏会导致整个文件系统不可用,在初始化的时候我们可以指定是否需要将superblock备份到每个block group上。
Block Group Descriptor
每个block group都有一个描述符与之对应,一般情况下每个block group内都会存储GDT的备份,但是在初始化的时候也可以指定是否需要将superblock和GDT备份到全部block group上,如果一个block group不含有这部分元数据,则该group一般就是从bitmap开始存储。一个block group descriptor记录该group中bitmap和inode table的位置信息,需要注意的是,一个group内位置固定的只有它的元数据(superblock和GDT),bitmap和inode的位置都部署固定的,这样便于将多个block group和成一个logic block group使用。
Block and inode Bitmaps
block bitmap记录了group内block的使用情况,inode记录了group内inode的使用情况。
Inode Table
Inode table会占用多个block来存储inode实例,每个inode实例对应系统上的一个文件。每个inode的id是全局唯一的,从1开始分配,同时每个group内inode的数目都是固定的(sb->s_inodes_per_group),所以通过(inode_num-1/ sb->s_inodes_per_group)就知道 一个inode位于哪个group之内。
Inode
如前文所述,一个inode对应于一个文件,每个inode都有个局部唯一性ID,用以存储该文件的元数据以及数据块指针,它的结构如下所示:
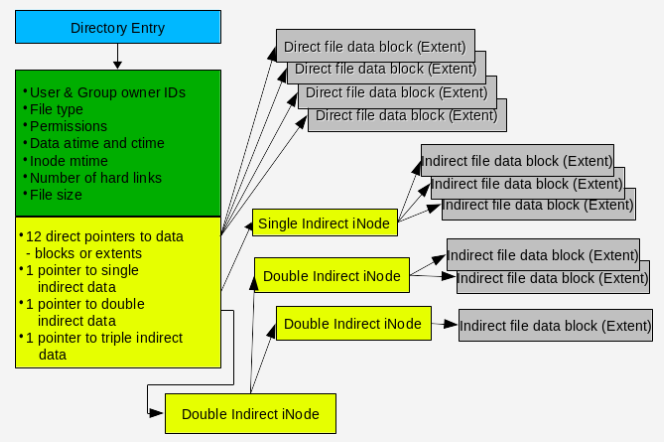
通常情况下,文件的碎片率不会不会很高,所以通常以及直接指针就够用了。在ext4中,inode的size是可以在初始化的时候指定的,我们可以利用更大的inode size来存储部分额外的用户元数据,这样能有效提升用户元数据的存储效率。
需要特别注意的是,一个inode是不包含文件名的,文件的访问需要通过directory entry来进行,下面来看目录项的具体内容。
Directory Entries
在ext4中,一个目录也是作为一个文件来管理,它的文件内容就是该目录下文件和其inode的对应关系,所以我们在访问一个文件时,都要先通过该文件所在目录的directory entry来获取到该文件的inode,这样才能访问该文件。。
通常情况下,一个目录项是以一种线性的方式来list它的所有entry的,当一个目录下存储的文件数过多的话,对应的directory entry就会非常大,这也是为什么ls一个大目录的时候需要很久才能返回结果。基于此考虑,ext3还引入hash tree的结构来存储一个目录的所有entry,如果EXT4_INDEX_FL这个flag在inode中设置了的话,对应的目录就是用这种hash tree的结构来组织和查找它的entries。
Journal
journal是在ext3引入的,用以提升文件系统的可靠性,防止系统奔溃导致文件系统的损坏。在修改系统内的重要数据之前,会先写入日志,待写入的数据持久化存储后,可以将对应的记录从日志中删除,当系统发生奔溃时,通过重放日志即可恢复数据。基于性能方面的考虑,默认情况下,ext4只有在修改元数据的时候才会写入日志,用户数据的修改是不会写入日志的,这个行为在挂载时也可以修改。如果默认的保护级别(data=ordered)不足,通过data=journal可以使所有数据在修改时都要写入日志中,这种方式虽然更安全,但是性能也会下降。