简介
Monitor是Ceph集群中的元数据管理组件,负责整个集群的元信息的维护,这里的元信息主要是几张抽象的map,包括osdmap、pgmap、monmap、mdsmap等。在Ceph集群中,OSD的设计原型为INTELLIGENT STORAGE DEVICES,通过这种智能的OSD可以减少Monitor作为中心节点的负担。在实际运行过程中,真正需要Monitor介入的主要是以下几种场景:
- Client在首次访问时需要从Monitor处获取集群crush map信息
- OSD节点会向Monitor节点汇报故障OSD的信息,Monitor需要修改对应map
- OSD在加入集群时,会向Monitor发送信息,Monitor需要修改对应map
整体来说,Monitor是基于改进的Paxos算法,对外提供一致的元信息访问及更新服务。
PAXOS
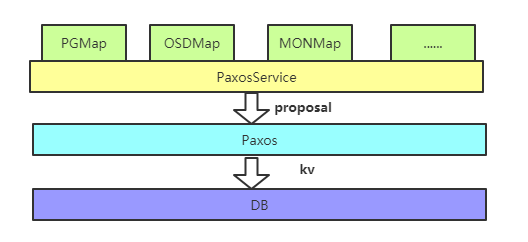
Monitor的整体架构如上图所示,整体分为4层,分别是DB层、Paxos层、PaxosService层及应用层。DB层用于提供单机KV存储服务,而PaxosService将应用层的不同元信息操作层封装成KV操作下发至Paxos层,Paxos层对上层提供一致性的KV存储服务,上层的不同PaxosService都共用一个Paxos实例。下面来看Paxos层是如何基于改进的Paxos算法来对外提供服务的。
Monitor中主要有两个角色,分别是leader及peon,其中只有leader能发提案,即leader对应于paxos中的proposer,peon及leader都是作为paxos中的acceptor存在,只要Monitor集群中半数以上
的节点存活,Monitor就能正常对外提供服务。下面先不看leader选举及异常恢复机制,
下面通过源码来看一个正常运行Monitor集群中paxos层是如何工作的。
一个paxos实例存在如下可能的状态:
- recovering:恢复状态,用于选主后各个实例之间的数据同步
- active:空闲状态,可以进入新的paxos流程
- updating:处于提案commit阶段
- updating-previous:恢复数据期间,实例处于提案commit阶段
- writing:提案正在写入
- writing-previous:恢复数据期间,实例正在写入提案
- refresh:等待刷新状态,获取lease后就可进入active状态
- shutdown:异常状态
一个Paxos实例的正常运行过程主要涉及到如下数据:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41private:
//当前实例上保存的最低版本已commit记录
version_t first_committed;
//上次提案的proposal number,一个leader在任期间pn是不会变的
version_t last_pn;
//当前实例上保存的最高版本已commit记录
version_t last_committed;
//已accept的最新proposal number
version_t accepted_pn;
//paxos会将提案的值以Transaction的方式记录在pendping_proposal中,一个Transaction
记录了一系列此次提案对应的操作。从这种形式也能看出来,paxos层一次只能对一个提案进行决议。
/**
* Pending proposal transaction
*
* This is the transaction that is under construction and pending
* proposal. We will add operations to it until we decide it is
* time to start a paxos round.
*/
MonitorDBStore::TransactionRef pending_proposal;
//pending_finishers中暂时存放提案被accept后的回调函数
/**
* Finishers for pending transaction
*
* These are waiting for updates in the pending proposal/transaction
* to be committed.
*/
list<Context*> pending_finishers;
//paxos流程开始后,committing_finishers中存放的是提案被选定后的回调函数
/**
* Finishers for committing transaction
*
* When the pending_proposal is submitted, pending_finishers move to
* this list. When it commits, these finishers are notified.
*/
list<Context*> committing_finishers;
Paxos的提案入口是在trigger_propose,如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39 bool Paxos::trigger_propose()
{
if (plugged) {
dout(10) << __func__ << " plugged, not proposing now" << dendl;
return false;
} else if (is_active()) {
dout(10) << __func__ << " active, proposing now" << dendl;
propose_pending();
return true;
} else {
dout(10) << __func__ << " not active, will propose later" << dendl;
return false;
}
}
void Paxos::propose_pending()
{
assert(is_active());
assert(pending_proposal);
cancel_events();
bufferlist bl;
pending_proposal->encode(bl);
dout(10) << __func__ << " " << (last_committed + 1)
<< " " << bl.length() << " bytes" << dendl;
dout(30) << __func__ << " transaction dump:\n";
JSONFormatter f(true);
pending_proposal->dump(&f);
f.flush(*_dout);
*_dout << dendl;
pending_proposal.reset();
committing_finishers.swap(pending_finishers);
state = STATE_UPDATING;
begin(bl);
}
从以上源码也可以看出来,一个提案首先是被持久存储在DB中的,这样可以保证提案被被提出后,即使paxos实例异常退出,提案数据也不会丢失。当一个paxos流程开始后,对应的提案会被从DB中取出,并开始决议过程。
begin(leader)
1 | // leader |
handle_begin(peon)
1 | // peon,处理leader发送过来的begin消息 |
handle_accept(leader)
1 | // leader,处理peon发送回来的accept消息 |
commit_start(leader)
1 | //leader,开始提案commit流程 |
commit_finish(leader)
1 | //leader,将commit操作下发至peon,刷写leader的状态 |
handle_commit(peon)
1 | //peon,处理leader发送过来的commit消息 |
至此,一轮提案决议过程就算完成了,monitor会发送ack信息给客户端,各个paxos实例便算完成了数据恢复和同步,leader的状态转换图如下所示:
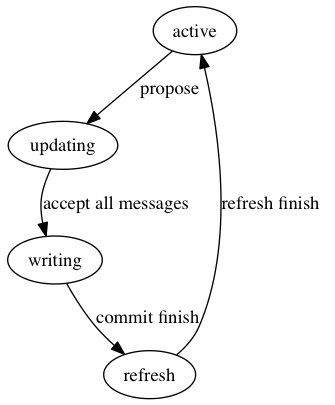
对应的转换操作如下:
- active-updating:接收到提案请求,将提案持久化存储,进入提案状态
- updating-writing:quorum的全部成员都同意此提案,开始提交提案
- writing-refresh:leader commit成功,并通知其他节点提交,开始刷新上层服务,通知上层可读
- refresh-active:刷新完成,一轮提案完成
peon的状态转换图如下所示:

peon在接收到提案后就进入updating状态,此状态期间是不提供读服务的,提案完成后接收到leader的lease后会重新进入active状态
异常恢复
下面分别以leader异常退出和peon异常退出为例来看数据是如何恢复的。
在看具体恢复例子时,要先清除整个paxos实例的一个状态转换图,清楚在每个状态异常退出时,数据是如何来恢复的,如下:
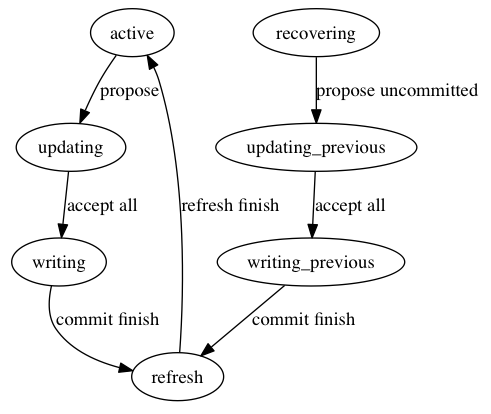
leader节点在选举成功之后会进入recovering状态用以尝试恢复数据,如果发现有未提交的数据,则会进入updating_previous状态,开始恢复数据,下面通过两种情况来分析monitor中paxos的恢复逻辑。
Peon down
peon节点down掉之后会触发选主流程,由于monitor是根据ip来选主的,原先的leader节点必定还会当选,且它的数据一定是最新的,leader节点只需进入数据恢复流程,尝试提交尚未commit的数据即可。
down的节点在之后加入集群后通过probing阶段便可同步数据,之后正常加入集群,leader节点不会变化
Leader down
leader节点可能down在任意状态,下面分别从leader down、leader up后集群如何恢复正常来看整个数据恢复流程。
down
leader down了之后,有新的peon节点当选为leader,leader节点可能down在以下几种状态:
- down在active状态,无需恢复数据
- down在updating状态,如果没有peon accept提案,则无需恢复数据。如果有的话,peon只需学习该提案即可
- down在writing状态,说明所有peon已经accept提案,新的leader会从新propose该提案
- down在refresh状态,说明老的leader已经成功提交提案,如果peon已经收到commit消息,则该提案会被学习到,若未收到的话,会重新propose该提案
up
leader节点在重新up后,会通过probing阶段做数据同步,当选为leader之后会进入数据恢复流程。
节点异常恢复分析需要重点关注下是否会存在数据丢失或者不一致的情况,peon节点down掉肯定不会造成数据丢失和不一致。唯一需要注意的是leader点down掉,如果数据已经commit了的话,peon处肯定是会持久存储的,所以不会有数据丢失,如果还有uncommited的数据的话,如果有peon已经接收的话,是会被重新学习的,所以不会造成数据丢失和不一致。
一致性达成
要保证强一致性的读取,有以下两个点需要注意:
- 如果防止读到过期的数据
- 如何防止读到尚未commit的数据
ceph-monitor中是通过租约机制来保证读的,持有lease的节点才能被读取数据,在提案过程之中所有节点的租约是会回收的,即提案过程中,paxos层是不可读的,这对于monitor这种典型的读多写少的场景也是一种合理的取舍。
同时通过以上的分析可知,每个提案是有一个版本号的,上层应用层在读取数据的时候需要带上版本号来读取数据,对于尚未commit的提案,是不可能会被读取到的,反应在应用层就是读请求会阻塞住,直至该提案可读。
定制化实现
与标准的multi-paxos或者其他paxos工程化实现,ceph-monitor中的paxos做了如下实现:
quorum:与其他共识算法实现很不同的是,ceph-paxos中quorum成员在选主之后就是固定的,之后所有的决议都要全部quorum成员的同意,任何一个quorum成员的变化都会触发重新选主。这样能简化paxos的实现,但是如果quorum成员变化频繁的话,ceph-paxos的可用性和性能就会受到很大影响。考虑到Monitor的节点数较少,这种取舍也是合理的
一次决议一个值:ceph-paxos一次只能决议一个值,同时对于决议值要求所有的quorum成员都应答,即不允许参与决议的节点存在日志空洞,前一条日志commit之后才能发起下个提案,这样能非常有效简化数据恢复流程。对于决议过程中的新提案请求,ceph-paxos层及上层的应用层都会进行聚合,这样能有效降低monitor的写入压力
读取:leader节点会给peon节点发放lease,持有lease的节点可以接收读请求,如果有提案在决议过程中,则取消peon的lease,防止读到旧的数据,提案commit之后peon节点会重新获得lease。通过每个提案会有个版本号,应用层读取数据时会带上此版本号用以读取最新的数据,通过这样的机制可以保证强一致性读,lease的引入对于monitor这种典型的读多写少的应用也是非常有效的