FBString是folly中关于std::string的实现,它更加精细地控制了内存的使用,在64位X86平台上,它的实现方式如下:
- 对于小字符串(0~23字节),直接将数据存储在栈内,不需在对上开辟空间,因为栈的访问效率较高
- 中等长度的字符串(24~254字节),在堆上开辟空间,发生拷贝时直接复制整个字符串
- 大长度的字符串(大于254字节),在堆上开辟空间,采用COW机制
定义
fbstring的定义如下:
1 | typedef basic_fbstring<char> fbstring; |
下面来看fbstring_core的实现。
构造
还是以最常见的std::string(“xxx”)这种构造方式为例来看它对应的构造函数:
1 | fbstring_core( |
如前文所述,对不不同的size,它的实现方式是不一样的,下面来逐个分析。
- Small
1 | template <class Char> |
由此可见,短字符串的内存结构如下所示:

由于需要一个字节存储size,另外需要一个字节存储结束符,所以small_中最多能存22个字节。
另外还有个问题就是字符串的类型(small、medium、large)是存储在哪的?答案就是同上图的size存在一起,即存在bytes_的最后一个字节中,如下所示:
1 |
因为前面也说到,短字符串的长度最多只有22个字节,存储这个长度不需要占用整个字节,所以可以用最后一个字节的高两位来存储字符串的类型,由此可见FBString对内存控制的精细度。
- Medium
1 | template <class Char> |
由此可见,中型字符串的内存结构如下所示:
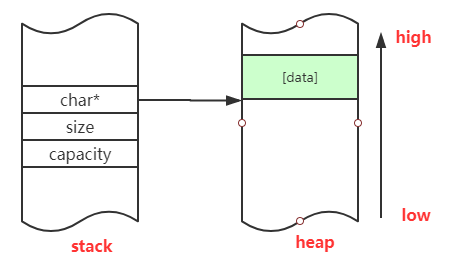
- Large
1 | template <class Char> |
大型字符串的内存分布同中型字符串基本相同,仅仅多了个引用计数需要存储,如下所示:
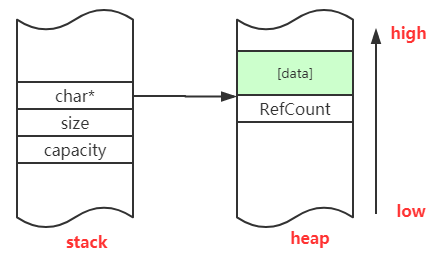
到此,还有个问题就是字符串的类别是如何存储的,代码如下所示:
1 | typedef uint8_t category_type; |
由此可见,basic_string栈中最后一个字节的高两位被用来存储字符串类型,在短字符串中,该字节存储的是字符串的size,由于此时size最多为22,所以高两位是不需要的,所以可以用来存类别,而在中大型字符串中,这两位对应于capacity中的最高两位,现有主机的内存没有这么大,所以这高两位也不可能用到,因此可以用来存储字符串类型。由此可见,FBString对内存的利用控制得多精细。
拷贝
看完了构造函数,下面来看拷贝构造函数:
1 | fbstring_core(const fbstring_core& rhs) { |
下面来分别看不同尺寸下的拷贝构造函数是如何实现的。
- Small
1 | template <class Char> |
- Medium
1 | template <class Char> |
- Large
1 | template <class Char> |
下面来看字符串的修改是如何实现的,显而易见的是,Large的修改会导致内存的重新分配,Small及Medium字符串由于是采用的eager-copy的方式,修改的时候直接返回对应的内存地址即可,以basic_string为例来看:
1 | //basic_string |
总结
- fbstring在std::string的基础上对于不同尺寸的string采用了不同类型的实现方式,对内存的使用控制非常精细。
- 短字符串直接存储在栈中从而避免内存分配
- 中型字符串采用了
eager copy的实现方式,因为folly鼓励使用jemalloc来替代glibc下默认的ptmalloc,内存使用使用很高效,开辟这样尺寸的内存可以认为是非常高效的 - 长字符串则采用了COW的实现,减少内存拷贝