函数压栈过程
以如下代码为例来分析C++中函数调用过程中,栈是如何变化的:
1 |
|
在Linux进程的地址空间中,栈是位于进程的高地址位置,且栈顶是向下增长的,每次的函数调用都有它自己独立的一个栈帧,用以记录这个函数调用过程中所需的信息,包括函数返回地址、参数、临时变量、保存的上下文等。其中有两个寄存器非常重要,分别esp和ebp,分别记录当前栈帧的栈顶位置和栈底位置,(对于X86-64平台上来说,对应的寄存器则为rsp及rbp),压栈使esp变小。一个典型的栈帧如下所示:
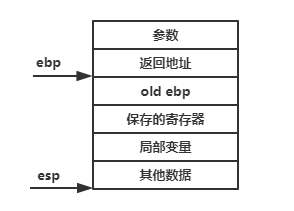
从参数开始的数据即是当前函数的栈帧,ebp的位置在运行过程中是固定的,而esp始终指向栈顶,在运行过程中是会发生变化的,而参数及返回地址之所以在ebp之上是因为这个两项是由该函数的调用者进行压栈的。ebp指向的old ebp是函数调用者的ebp值,这样该函数退出后通过old ebp即可恢复调用者的栈帧。
将示例代码编译后,通过gdb进行反汇编,首先来看main函数,如下所示:
1 | (gdb) disassemble main |
可以看到,参数是在调用foo之前传入的,参数可能是通过压栈的方式传入,也可能是通过寄存器传递,其中call指令用以调用foo函数,该指令也会将函数的返回地址进行压栈。下面来对foo进行反汇编,如下所示:
1 | (gdb) disassemble foo |
从上述代码也可总结出,c++中一个函数调用(foo)过程是这样的:
- 把该函数的所有或者部分参数入栈,或者将参数存入寄存器中
- 把当前指令的下一条指令压如栈中
- 跳转到函数
foo内部执行 - 将调用者的
ebp值压栈保存(push ebp) - 重置
foo函数的栈帧(mov ebp esp) - 执行相关操作
- 执行完函数
foo之后,恢复调用者的栈帧(pop ebp) - 跳转到下一指令继续执行
函数返回值传递
通过前文的发汇编代码也可看到,函数的返回值是通过eax来返回的,但是eax只能存储4个字节,那么对于大于4个字节的返回值是如何传递的呢,以如下代码为例来看:
1 |
|
main函数的反汇编结果如下所示:
1 | (gdb) disassemble main |
从main函数的反汇编结果也可看出,前两个函数是分别是通过eax及rax来返回的。首先来看test4Bytes,如下所示:
1 | (gdb) disassemble test4Bytes |
如前文所述,4个字节的函数返回值是通过eax来传递的。而test8Bytes的反汇编结果如下:
1 | (gdb) disassemble test8Bytes |
可以看出,此时8个字节的返回值是通过rax来返回的,这个对于不同平台的实现来说可能是不一样的,例如在32位的机器上,一般是通过eax和edx组合来返回8个字节的返回值。上述main函数的反汇编代码中有段保护机制,为了简化无关代码的干绕,关闭端保护机制编译如下代码(g++ -fno-stack-protector ):
1 |
|
从main的反汇编结果可以看出,它先是分配了64字节的一个堆栈空间,然后将该地址空间保存在rax中,然后将rax的值传入rdi中,紧接着便调用testMoreBytes函数,显而易见的是它是要将分配的这一段空间传递给testMoreBytes函数。而通过testMoreBytes的反汇编结果可以看出,它显示从rdi中取出这段地址,并将地址赋值给rax,最后再将值拷贝到这段地址空间处,所以此时函数返回值的传递过程是:
main函数会在堆栈中额外开辟一段空间,用以存储返回值- 将上述空间的地址传递给
testMoreBytes函数,函数内部将值拷贝到该空间处 main函数通过该端空间来读取返回值