LevelDB中主要有以下几种文件:1
2
3
4
5
6
7
8
9enum FileType {
kLogFile,
kDBLockFile,
kTableFile,
kDescriptorFile,
kCurrentFile,
kTempFile,
kInfoLogFile // Either the current one, or an old one
};
对应的文件作用如下:
- kLogFile:WAL日志文件,文件名为[0-9]+.log
- kDBLockFile:db锁文件,文明名为LOCK,通过LOCK文件加文件锁(flock)来实现只有一个实例能操作db
- kTableFile:sstable文件,文件名为[0-9]+.sst
- kDescriptorFile:db元数据文件,存储系统中version信息,文件名为MANIFEST-[0-9]+,每当db发生compaction时,对应的versionedit会记录到descriptor文件中
- kCurrentFile:记录当前使用的descriptor文件名,文件名为CURRENT
- kTempFile:临时文件,db在修复过程中会产生临时文件,文件名为[0-9]+.dbtmp
- kInfoLogFile:db运行过程中的日志文件,文件名为LOG
下面主要来分析kLogFile文件、kTableFile。
kLogFile
kLogFile是以block为单位组织的,除了文件结尾的block外,每个block的大小为32KB。每个block由若干填入record组成,如下所示:1
2
3
4
5
6
7
8Each block consists of a sequence of records:
block := record* trailer?
record :=
checksum: uint32 // type及data部分数据的校验值,大小为4B,用小端序存储
length: uint16 // data部分的长度,大小为2B
type: uint8 // FULL, FIRST, MIDDLE, LAST中的一个,大小为1B
data: uint8[length] //存储实际数据
block的示意图如下:

每个record的示意图如下:
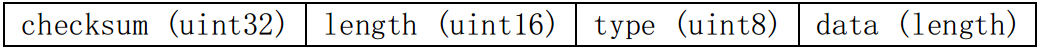
一个record不会从block的最后6B的位置开始写入(因为一个record至少为7B),所以一个block可能会以trailer结尾,此部分位置会全部填0,读取该block时该部分数据会被跳过。由于每个block的大小固定,一条wal日志可能需要被切分到多个block中的record中存储,type这个字段记录的便是这个record的类型,目前只有上文所列的四种类型。FULL表示当前record存储的是一条完整的日志,FIRST、MIDDLE、LAST分别代表一条日志的头部、中部、尾部三个部分,通过多个record的拼接可还原出一条完整的日志。
log写入
1 | AddRecord(const Slice& slice) { |
log读取
1 | ReadRecord(Slice* record, std::string* scratch) { |
kTableFile
kTableFile是db中持久化存储数据的文件,它也是以block的形式来组成文件,整体上看,它主要有数据block、元数据block组成,由于kTableFile文件尺寸可能较大,读取时如果从头扫描这个文件会造成读取效率低下,所以kTableFile文件中也存储data block及meta block的索引信息来加速读取,整体格式如下:1
2
3
4
5
6
7
8
9
10
11
12<beginning_of_file>
[data block 1]
[data block 2]
...
[data block N]
[meta block 1]
...
[meta block K]
[metaindex block]
[index block]
[Footer] (fixed size; starts at file_size - sizeof(Footer))
<end_of_file>
整体示意图如下:

其中,data_block存储的实际kv数据,index block中保存的是每个data block的last key及其在文件中的索引(偏移量,大小),当前版本中,meta block及metaindex block均未实现。Footer是文件尾部固定长度的块,存储的是metaindex block及index block的索引信息。
每个data block在生成时,会在其尾部存储1B的type和4B的crc,分别记录该block的压缩类型及数据校验值。Block中的每个record(rentry)存储了一条kv数据,由于key是连续的,系统会key采用前缀压缩的方式来减少所需存储空间,只需存储当前key的不同部分,前缀可以从之前的key中获取出来。Block的结构如下:
1 | Block := entry* |
例如第一个key为sam,第二个key为samon,则第二条记录只需存储on这部分数据,前缀可以根据前一个key获取出来,此时该entry对应的各部分如下:1
2
3shared_bytes: 3
unshared_bytes: 2
key_dalta: on
通过这种前缀压缩的方式可以降低所需存储空间。此外,如果一个block完全按照前文所述逻辑进行压缩,每次查找key的时候都要从头开始遍历,这样的查找效率可能较低。所以系统进一步细化了粒度,采用分段压缩,每个段内的key都以第一个key开始做前缀压缩,这第一个key就被称作重启点,block中所有重启点的偏移值和数量都会记录在trailer中。
References
- 淘宝leveldb的实现
- 庖丁解LevelDB之数据存储