作用
LevelDB中将随机写在内存中缓存并进行排序(memtable),从而将随机写转化成顺序写来提高数据的写入速度,在磁盘上它是以sstable的格式来持久化存储数据的。磁盘上的sstable文件是分层存储的,层级越高,容量就越大,存储的文件就越旧。随着数据的持续写入,memtable达到阈值之后会flush到level 0的sstable中,这个过程被称之为minor compaction,由于这一层级的文件是有memtable直接刷写下来的,所以sstable之间的key可能会存在重叠。
在查找一个key时,系统会先去memtable中查找,若未找到,则会按层级去sstable中查找。由于level 0中的sstable中的key是可能重叠的,所以在查找level0时可能要遍历多个sstable文件,这样会导致查询效率较低。所以当level 0中的文件数较多时,会出发major compaction,将该层的文件同下层合并。
level 0以上的文件是通过compaction来生成的,所以同一层的文件之间的key是不存在重叠的,但是该层的文件量也不能太大,否则会降低key的查找效率。同时,文件量太大也会造成major compaction的时候IO负载过高,影响系统的正常读写。所以LevelDB中会分多层来存储sstable文件,层级越高,容量越大,所存储的文件也越久。
综上,Compaction的机制如下:
- 当memtable达到阈值时,会触发minor compaction,将memtable中的数据flush成sstable文件,防止占用过多内存
- 当level 0中的文件数过多时,会触发major compaction,将该层的部分文件与上层合并,提高查询效率
- 当level 0以上某层文件总量过大时,会触发major compaction,提高查询效率,同时避免之后参与compaction的数据量过大
流程
Compaction
Compaction最终是通过调用BackgroundCompaction来执行的,执行流程如下:
1 | BackgroundCompaction() { |
整体的流程图如下:
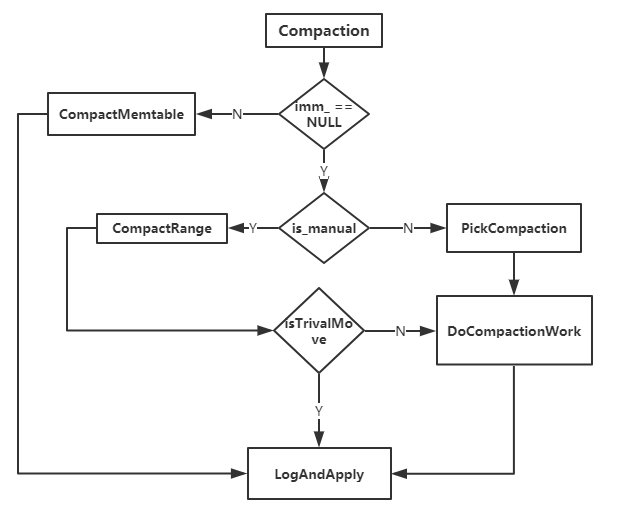
Minor Compaction
其中,CompactMemtable用以将memtable中的文件flush成sstable文件,它的流程如下:
1 | CompactMemtable() { |
以上流程中,Version是系统用来管理系统中sstable文件的,每次进行compact后,都会新生成一个Version用来管理磁盘上sstable文件的状态,VersionEdit则代表此次compact中文件的变化情况,关于Version机制会在下节讨论。
在CompactMemtable中会调用WriteLevel0Table将memtable刷写至sstable中,机制如下:
1 | WriteLevel0Table(MemTable* mem, VersionEdit* edit, Version* base) { |
其中,需要注意的是,memtable不总是直接flush值level 0中的,如果level 0中没有文件与memtable的数据重合,则可以直接刷写至更高的层级,这样可以减少compaction的次数。但同时,如果某一层(level层)没有文件与memtable中的数据重合,但是下一层(level+1)中与memtable中重合的文件尺寸较大,也不能直接放入level中,否则的话会导致之后该文件compaction的时候设计到的数据量太大,影响系统的正常读写。
Major Compaction
Major Compaction的第一步是选择生成compaction的信息,根据compaction是否是手动触发的,具体机制又有不同,如下:
1 | //根据手动compact时输入的level及key的范围生成compact信息 |
生成compaction信息后,便可开始compaction流程,如果level+1没有文件与待compaction的文件存在重叠,则可以考虑将文件直接下移,但是下移后也不能造成之后的compaction数据量过大,LevelDB这里是通过grandparent层级(level+2)的重叠数据量来判断的:
1 | IsTrivialMove() { |
如果不是直接平移,则调用DoCompactionWork来修改sstable,机制如下:
1 | //根据输入在高层生成新的sstfile |
其中,LogAndApply是根据VersionEdit来生成新的version,并将新生成的version数据append到manifest中来进行持久化存储,这部分会在下节展开。
Version
Version机制作用简要概括如下:
- 维护sstfile的索引信息,包括每层由哪些文件,每个文件的key range等
- 根据sstfile信息,生成compaction相关的信息
- 在每次compaction后,将元数据持久化至manifest中,供DB启动或恢复时加载
- 维护版本信息,在此基础之上生成快照
Version机制涉及到数据结构主要有三个:Version,VersionEdit,VersionSet,其中每个Version都记录了当前sstfile的索引信息,每次compaction后都会生成一个新的version,而这次compaction的文件变化情况就是用VersionEdit来记录的,简单来说就是:
1 | version0 + versionedit = version1 |
此外,为了支持快照及MVCC,老的version不会马上就删除,而是通过VersionSet来管理,VersionSet中所有的version是通过双向链表来连接的,这样可以方便地查找各个version对应的数据,简单来说就是:
1 | versionset = version0 + version1 + ... + currentversion |
如下所示:
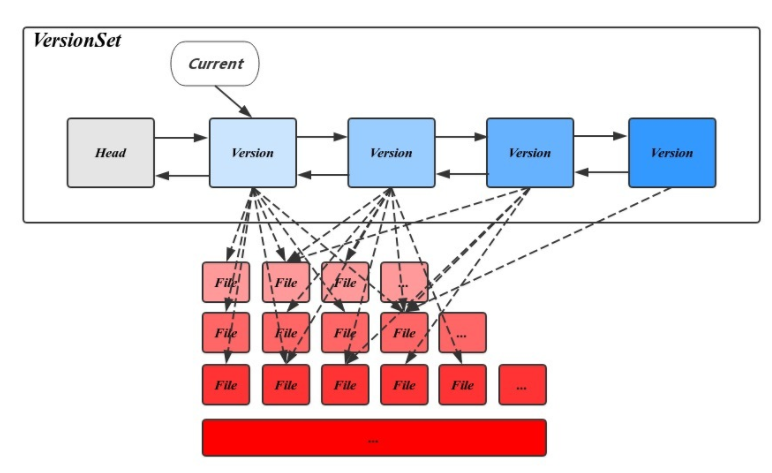
VersionEdit
VersionEdit的主要结构如下,它记录了一次compaction后sstfile的变化信息,包括新增哪些文件、删除哪些文件、某个level参与compaction的最大key是什么:
1 | //一个VersionEdit总是与一次compaction相关 |
Version
LevelDB是通过version来记录数据库是有哪些sst文件组成的,每次compaction后都会生成新的version,version是LevelDB实现快照和MVCC的基础,它的主要结构如下:
1 | class Version { |
其中一个很重要的成员是引用数。。在一次compaction后,需要删除的sst文件并不会立马删除,因为此时可能会有读请求或者快照仍需要查找旧的文件来获取数据,这都是通过引用计数来控制的。一个version在生成时默认引用数为1,引用数变为0的时候便可以删除,当读请求释放或者该version不是最新版本时,refs_都会减1。总的来说,LevelDB的MVCC和快照机制是由一下几个部分组成:
- sst文件是不可变的,在compaction的时候也不影响read
- 每个key在内部存储时都会带上SequenceNumber,打快照时只需记录对应的SequenceNumber即可
- version通过引用计数来保证资源的有效性,防止write影响read或者影响快照
VersionSet
VersionSet管理系统当前所有version,并负责这些元数据的持久化,其中最重要的方法就是LogAndApply,在每次version发生变化时该方法都会被调用,根据VersionEdit生成一个最新的Version,并 插入链表头部,持久化存储在manifest中,如下:
1 | LogAndApply(VersionEdit* edit, port::Mutex* mu) { |
触发机制
LevelDB中总共有以下几种情况会出发compaction:
- memtable达到阈值时会出发minor compaction
- 手动触发:系统提供结构供用户指定key range及level来出发compaction,默认情况下,手动触发的compaction比自动触发的高
- 文件数触发:由于level 0中的文件间key range可能存在重叠,所以需要严格控制该层的文件数,该层的文件数大于阈值的时候并发触发major compaction
- 容量触发:level 0之上的文件需要严格控制容量,提高查询效率和避免过大的数据参与compaction,所以当level 0上某层的总数据量超过阈值时,便会触发major compaction
- seek触发:系统在查找Key时会记录查找次数,由于每次查找都会消耗额外的IO,当查找次数过多时,对应的IO消耗会大于一次compaction所带来的IO,此时系统会触发compaction来降低某些key的查找次数