下面以X86平台下32为机器为例来分析Linux的内存管理机制。
用户进程内存管理
在多任务操作系统上,每个进行都是运载自己的内存空间里,这就是虚拟内存,在32位机器上,这个虚拟内存空间拥有4GB的寻址能力,通过页表(page table)我们可以将虚拟内存映射成真是的物理地址。Linux默认会将高地址的1GB空间分配给内核使用,剩下的3GB作为用户空间供用户使用,整体的进程地址空间布局如下:
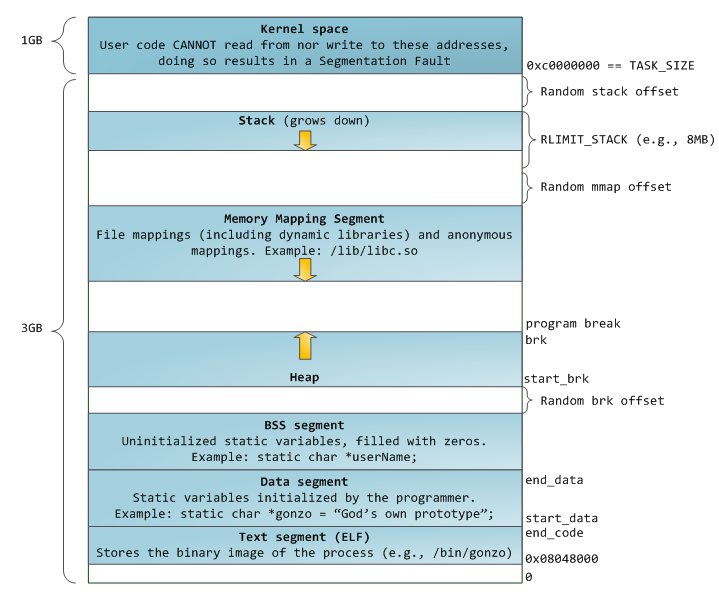
对应的主要区域如下:
- 内核空间:供操作系统内核使用,用户态程序不能访问
- 栈:维护函数调用的上下文,向下增长,通常有数M大小。通过系统调用expand_stack()可以将分配栈空间,如果栈空间无法增长了(通常已经到8MB)了,则会发生栈溢出
- 堆:应用程序动态分区内存区域,通过brk系统调用来向上增长
- 内存映射区:通过mmap分配,用以映射共享库或映射一个匿名空间供程序使用。mmap是一个高效、方便地操作一个文件,通过mmap将动态库映射至内存中可以实现快速加载,或者通过mmap映射出一个不跟任何文件关联的匿名空间来供用户程进程使用。在Linux中,如果你通过malloc申请一块打内存的话(通常是大于128KB),glibc通常会调用mmap系统调用来分配内存
- BSS、DATA、TEXT:存储用户程序数据段、代码段等。其中BSS、DATA存储的都是存储程序全局或静态变量,不同的是BSS存储的是为初始化的变量
如上图所示,每个段之间可能会有部分随机偏移值,即每段的开始位置并不是固定的,这样有利于降低被攻击的风险。通过/proc/{pid}/maps这个文件,可以观察进行的内存使用情况。
内核空间内存管理
如下图所示,Linux中的进程实例是通过task_struct这样一个结构来描述的,该结构中的mm这个域指向一个内存描述符mm_struct,记录了进程执行期间它的内存摘要。如图所示,它存储了进程中每个段的起始位置、物理页的数目、虚拟空间的使用情况等。
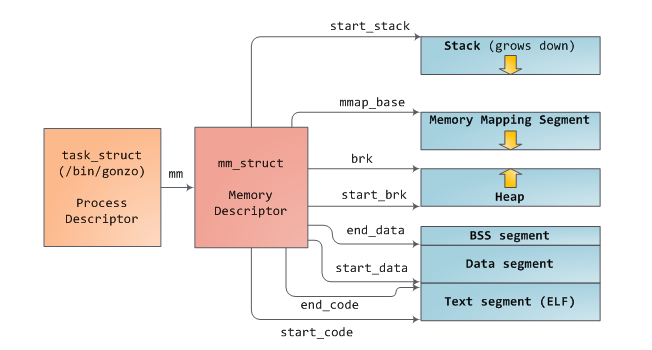
在内存描述符中(mm_struct),我们还可以找到两个重要的结构:虚拟内存区域集合(the set of virtual memory areas )及页表(page tables)。如下,为一个内存区域集合:
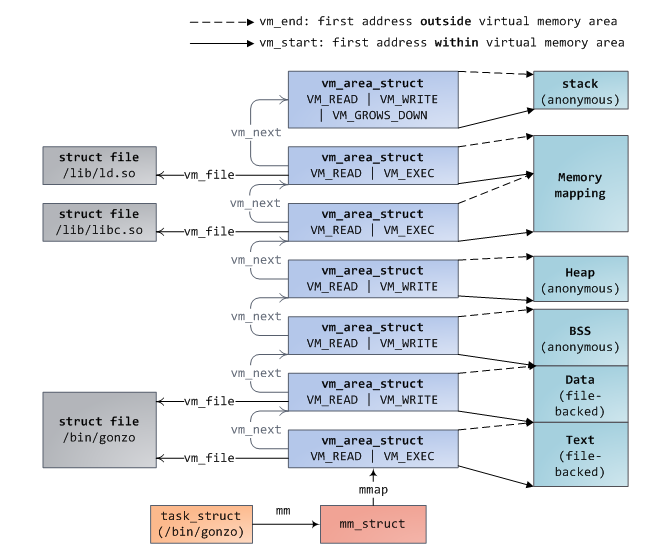
每个VMA(virtual memory area)是一段连续的、不会重叠虚拟地址,一个vm_area_struct实例完整得描述了一个内存区域,包括起始、结束地址,flags描述的访问权限及行为,以及vm_file描述的对应的映射文件(如果有的话,没有的话这段内存区域就是匿名的)。
一个进程的VMA会以两种形式存储在存储在其内存描述符中:以链表的形式存储在mmap域中,以红黑树的心事存储在mm_rb域中。红黑树的形式使得内核可以快速查找出给定虚拟地址对应的内存区域,当我们读取/proc/{pid}/maps文件时,内核可以快速恢复出其VMA链表。
Linux在通常情况下会使用4KB大小的页来映射用户空间的虚拟空间,处理器会通过页表(page tables)来将虚拟地址转换为物理地址,Linux在内存描述符的pgd域中存储了指向进程page tables的指针,每个虚拟内存页在page tables里都会有一个页表项(page table entry(PET))与之对应,通常来说,PTE在x86架构下是一个大小为4byte的记录,如下所示:

如上各个位的作用如下:
- P:标识该虚拟页是否在内存中,0表示不在内存中,访问该页会出发缺页异常
- R/W:标识是否可读/写,如果为0,则页面为只读
- U/S:标识是用户/管理员,如果为0,只能供内核使用
- D:标识是否为脏页面,脏页面表示执行过写操作
- A:标识是否被访问过
虚拟内存并不存储任何东西,仅仅是将一个进程的地址空间映射至真实的物理地址空间上。这个物理地址空间被内核切分成一个个页帧(page frames),它是物理内存管理的最小单位,32为X86架构下,Linux通常采用4KB大小的页帧,每个页帧在内核中都有一个描述符和标志位进行追踪。下面我们把VMA,PTE、page frame连起来看它们是如何工作的,如下所示为一个用户堆内存:
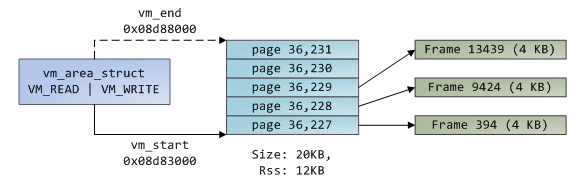
蓝色矩形表示VMA范围内的页,箭头表示通过PTE将虚拟页映射至page frame,没有箭头指出的虚拟页,意味着这个页的P flag为0,即这个虚拟页从来没有被访问或者刚被置换出来。VMA就是进程与内核之间的签约,进程对内核发起请求(内存分配,文件映射等),内核同意后创建或者更新对应的VMA,但它不是立即就将虚拟页映射至物理页,而是在发生缺页异常的时候才会真正映射,所以实际情况是VMA记录进程同内核达成的协议,PTE记录内核实际已经执行了哪些操作。以下为内存分配的一个例子:
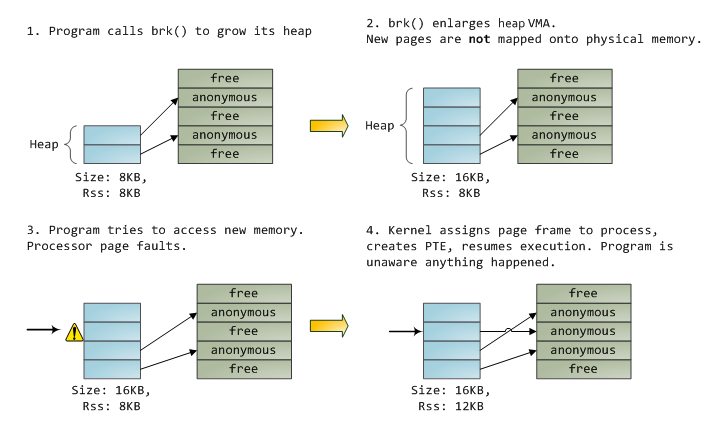
当进程通过brk()申请申请内存时,内核只是更新对应VMA后便返回,并没有实际的物理页被分配,当进程访问这个页时,内核会去寻找对应的VMA,如果找到了会做前置检查(读写权限等),如果没找到,说明进程访问了不合理的位置(即之前未与内核达成合同),这就会出发段错误。找到VMA之后,内核会通过查找PTE内从及VMA的类型来解决这个缺页异常(page fault),此时PTE内容为空,之后内核便会分配一个页帧并将PTE指向分配的页帧。
Page Cache
操作系统在操作文件时有两个问题需要解决:
- 相对于内存来说,硬盘的读取速度非常慢
- 需要做到将文件加载至内存中 一次便可供多个进程共享
以上两个问题都可以通过page cache来解决,kernel用它来存储与页面大小相同的文件块。下面用一个render程序为例来描述一个文件的读取过程,render会打开scene.dat文件,每次读取512 byte的内容并将其存入堆内存中,读取流程如下:

读取挖12KB后,render的堆内存及相关页帧如下:
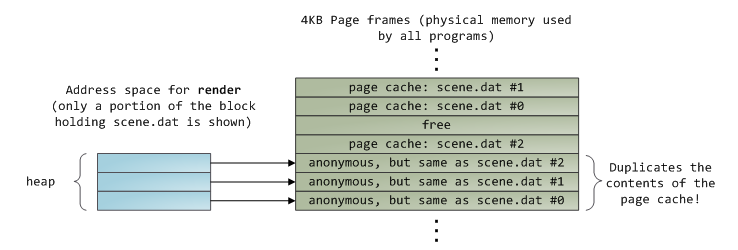
事实上,尽管只调用了read函数,此时也会有三个page cache的页帧中存储了部分scene.dat的部分数据,因为所有的常规文件操作都是通过page cache来进行的,在x86平台上,所有文件在内核看来都是一系列4KB大小的块。即使你只是读取1byte数据,它所在的4KB大小的块都会被复制到page cache中。
不幸的是,为了是用户态程序读取文件内容,内核还需要将page cache中的东西复制到用户内存中,这不但会消耗cpu,同时也会浪费物理内存。如上图所示,scene.dat的内容在内存中存储了两份,而且每个实例都会保存一份。至此,这种读取方式虽然解决磁盘延迟的问题,但会带来较多额外的问题,但使用memory-mapped files却可以解决这些问题,即通过内核将进程的虚拟页面直接映射至page cache中,这样能有效提高文件读写效率,同时也能节省部分物理内存,如下所示:
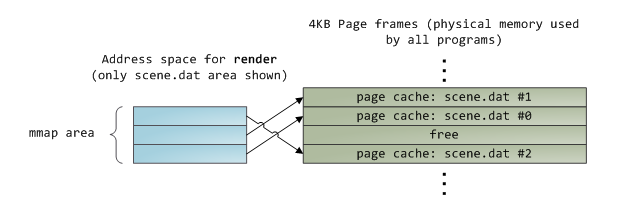
在使用了page cache的读写时,当进程调用write()时,数据只是被写入到page cache中,对应的页进入dirty状态,磁盘IO不会立刻发生,如果此时主机死机,数据就会丢失,因此重要的数据在写入时必须调用fsync(仍需要注意磁盘驱动缓存)。另一方面,读取操作会阻塞住,直至数据准备好,内核会通过eager loading(积极加载)来加速读取,即预读取部分数据至page cache中。最后,你可以通过O_DIRECT来绕过page cache。
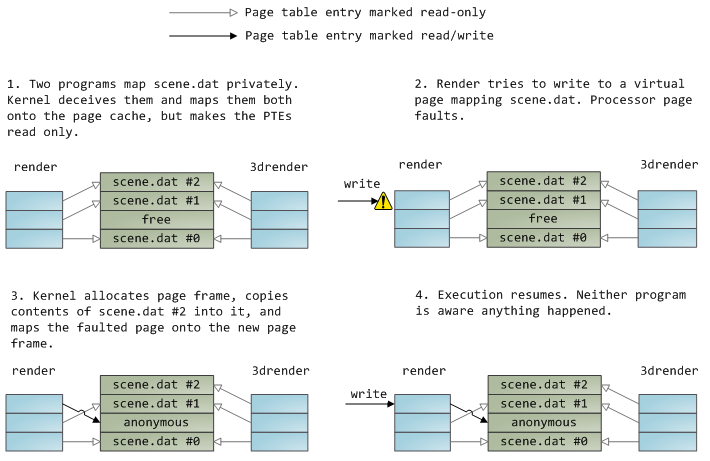
一个文件映射可以是私有的,也可能是共享的,这种区别只有在更改内存中的内容时才能体现出来:私有映射时进程对内存的修改不会提交至磁盘中或者被其他进程所见,而共享映射却可以。内核通过页表项,使用copy on write来实现私有映射。如下示例中,render和render3d同时创建了scene.dat的私有映射,render修改了映射至内存中的文件: